











Современная ИТ‑инфраструктура генерирует значительные объёмы данных: метрики серверов, состояние сети, логи приложений, события безопасности. Однако сами по себе необработанные данные не дают понимания реальной картины. Чтобы превратить поток метрик в основу для принятия решений, нужна связка инструментов мониторинга и визуализации.
В этой статье рассмотрим, как выстроить эффективную систему наблюдаемости, которая будет полезна и инженерам, и руководителям, на примере российских решений «Пульт» и «Графиня».
Разобраться в теме нам помогает Дмитрий Унтила, CPO «Пульта» и «Графини» в «Лаборатории Числитель», более 10 лет работающий с системами мониторинга.
В этой статье рассмотрим, как выстроить эффективную систему наблюдаемости, которая будет полезна и инженерам, и руководителям, на примере российских решений «Пульт» и «Графиня».
Разобраться в теме нам помогает Дмитрий Унтила, CPO «Пульта» и «Графини» в «Лаборатории Числитель», более 10 лет работающий с системами мониторинга.
Почему мониторинг — основа стабильной ИТ‑инфраструктуры
Рынок систем мониторинга прошёл несколько этапов развития. Ещё 15−20 лет назад в этой области доминировали крупные вендоры: IBM, BMC, HP. Их решения обладали широкой функциональностью, но требовали значительных бюджетов и выделенных команд для поддержки.
Экономические кризисы изменили ситуацию. Компании начали сокращать расходы, и системы мониторинга нередко попадали под оптимизацию первыми. На первый план вышел open source: Zabbix, Nagios, Prometheus, Elastic Stack. Инфраструктурный мониторинг на базе этих решений стал стандартом де-факто. На их основе выстраивались комплексные системы: Elastic для логов, Zabbix для инфраструктуры, Grafana для визуализации.
Сегодня появился новый фактор — требования импортозамещения. Использовать зарубежный open source в ряде структур уже невозможно. Именно поэтому «Лаборатория Числитель» в 2023 году выпустила «Пульт» — форк Zabbix, дополненный новым функционалом и внесённый в реестр российского ПО, а летом 2025 года — «Графиню», российский аналог Grafana, разработанный с нуля.
Экономические кризисы изменили ситуацию. Компании начали сокращать расходы, и системы мониторинга нередко попадали под оптимизацию первыми. На первый план вышел open source: Zabbix, Nagios, Prometheus, Elastic Stack. Инфраструктурный мониторинг на базе этих решений стал стандартом де-факто. На их основе выстраивались комплексные системы: Elastic для логов, Zabbix для инфраструктуры, Grafana для визуализации.
Сегодня появился новый фактор — требования импортозамещения. Использовать зарубежный open source в ряде структур уже невозможно. Именно поэтому «Лаборатория Числитель» в 2023 году выпустила «Пульт» — форк Zabbix, дополненный новым функционалом и внесённый в реестр российского ПО, а летом 2025 года — «Графиню», российский аналог Grafana, разработанный с нуля.

Инструменты мониторинга: что важно учитывать
Инфраструктурный мониторинг отслеживает состояние серверов, сетевого оборудования, систем хранения данных и других компонентов инфраструктуры. При этом инструменты мониторинга сети, серверов и СУБД (систем управления базами данных) часто существуют разрозненно: каждая система собирает свои метрики, генерирует свои события и имеет собственный интерфейс.
Данные в компаниях, как правило, уже есть: работает CMDB (база данных конфигурационных элементов инфраструктуры), развёрнута система мониторинга, ведётся справочник ответственных инженеров. Но эти данные неоднородны и находятся в разных системах без взаимосвязей между ними.
Инструменты мониторинга и контроля должны не только собирать метрики, но и предоставлять возможность их анализа в едином интерфейсе. Это ключевой момент: без визуализации данных вы получаете набор необработанных метрик, которые не дают понимания общей картины. Вы видите, что загрузка CPU (центрального процессора) на сервере составляет 87%, но без контекста невозможно определить, является ли это нормой или требует вмешательства.
Практика показывает, что во многих компаниях нет отдельного подразделения мониторинга. Чаще всего это дополнительная нагрузка на администратора или DBA-специалиста (администратора баз данных). Именно поэтому инструменты мониторинга должны быть понятными и не требовать глубокой экспертизы для базового использования.
Данные в компаниях, как правило, уже есть: работает CMDB (база данных конфигурационных элементов инфраструктуры), развёрнута система мониторинга, ведётся справочник ответственных инженеров. Но эти данные неоднородны и находятся в разных системах без взаимосвязей между ними.
Инструменты мониторинга и контроля должны не только собирать метрики, но и предоставлять возможность их анализа в едином интерфейсе. Это ключевой момент: без визуализации данных вы получаете набор необработанных метрик, которые не дают понимания общей картины. Вы видите, что загрузка CPU (центрального процессора) на сервере составляет 87%, но без контекста невозможно определить, является ли это нормой или требует вмешательства.
Практика показывает, что во многих компаниях нет отдельного подразделения мониторинга. Чаще всего это дополнительная нагрузка на администратора или DBA-специалиста (администратора баз данных). Именно поэтому инструменты мониторинга должны быть понятными и не требовать глубокой экспертизы для базового использования.
DevOps‑мониторинг: подход и особенности
Мониторинг DevOps‑инфраструктуры представляет собой отдельное направление со своими требованиями. Для разработчиков и DevOps-инженеров важна прежде всего скорость: они проверяют гипотезы, им необходима автоматизация и интеграция с CI/CD‑пайплайнами (конвейерами непрерывной интеграции и доставки кода).
DevOps‑мониторинг должен работать с минимумом ручной настройки. Здесь не требуется глубокая кастомизация, нужны готовые интеграции и автоматическое обнаружение сервисов. В микросервисной архитектуре стандартом стали Prometheus и Victoria Metrics для сбора метрик с контейнеров. Эти решения справляются со сбором данных, но и здесь остаётся потребность в визуализации ИТ‑метрик. Традиционно эту задачу решала Grafana, а теперь появился отечественный аналог «Графиня».
DevOps‑инженеры отличаются от дежурной смены и служб эксплуатации ритмом работы, набором инструментов и ожиданиями от системы визуализации.
DevOps‑мониторинг должен работать с минимумом ручной настройки. Здесь не требуется глубокая кастомизация, нужны готовые интеграции и автоматическое обнаружение сервисов. В микросервисной архитектуре стандартом стали Prometheus и Victoria Metrics для сбора метрик с контейнеров. Эти решения справляются со сбором данных, но и здесь остаётся потребность в визуализации ИТ‑метрик. Традиционно эту задачу решала Grafana, а теперь появился отечественный аналог «Графиня».
DevOps‑инженеры отличаются от дежурной смены и служб эксплуатации ритмом работы, набором инструментов и ожиданиями от системы визуализации.
Зачем нужна визуализация ИТ‑данных
Визуализация выступает связующим звеном между необработанными метриками и управленческими решениями. Когда несколько источников данных подключены к единой платформе, вместо разрозненных графиков появляется целостная картина состояния инфраструктуры.
«Графиня» работает по тому же принципу, что и Grafana. Источники данных (системы мониторинга, СУБД, справочники) подключаются к платформе, данные агрегируются и выводятся на интерактивные дашборды. На текущий момент поддерживаются Zabbix и его форки (включая «Пульт»), Prometheus, Victoria Metrics, PostgreSQL, CSV и JSON, GitLab, Elasticsearch и Clickhouse.
При правильном построении визуализация позволяет создать полноценный инструмент для решения задач всей компании. Данные из разных источников объединяются в единые интерактивные витрины, доступные различным категориям пользователей.
«Графиня» работает по тому же принципу, что и Grafana. Источники данных (системы мониторинга, СУБД, справочники) подключаются к платформе, данные агрегируются и выводятся на интерактивные дашборды. На текущий момент поддерживаются Zabbix и его форки (включая «Пульт»), Prometheus, Victoria Metrics, PostgreSQL, CSV и JSON, GitLab, Elasticsearch и Clickhouse.
При правильном построении визуализация позволяет создать полноценный инструмент для решения задач всей компании. Данные из разных источников объединяются в единые интерактивные витрины, доступные различным категориям пользователей.
Визуализация для инженеров и руководителей: в чем разница
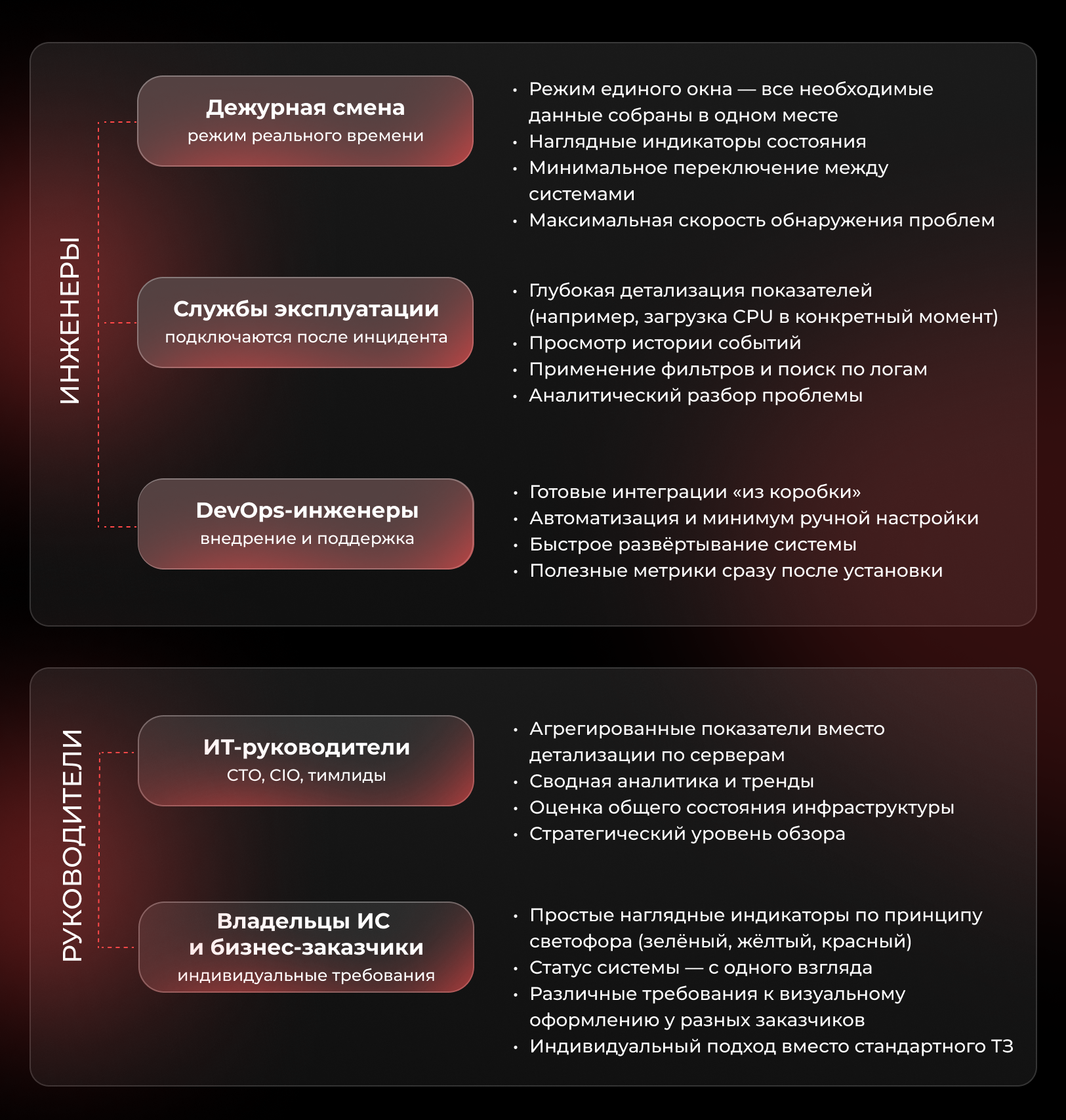
У разных групп пользователей сильно отличаются потребности в визуализации. Понимание этих различий — ключ к построению эффективной системы.
Для инженеров
Дежурная смена работает в режиме реального времени. Основное требование — режим единого окна: все необходимые данные собраны в одном месте, индикаторы состояния наглядны, переключение между системами сведено к минимуму. Визуализация для инженеров дежурной смены должна обеспечивать максимальную скорость обнаружения проблем.
Службы эксплуатации подключаются, когда проблема уже зафиксирована. Для них на первый план выходит глубокая детализация: возможность проанализировать загрузку CPU в конкретный момент времени, просмотреть историю событий, применить фильтры и выполнить поиск по логам.
DevOps-инженеры нуждаются в готовых интеграциях, автоматизации и минимуме ручной настройки. Им важно, чтобы система разворачивалась с минимальными усилиями и сразу предоставляла полезные метрики.
Службы эксплуатации подключаются, когда проблема уже зафиксирована. Для них на первый план выходит глубокая детализация: возможность проанализировать загрузку CPU в конкретный момент времени, просмотреть историю событий, применить фильтры и выполнить поиск по логам.
DevOps-инженеры нуждаются в готовых интеграциях, автоматизации и минимуме ручной настройки. Им важно, чтобы система разворачивалась с минимальными усилиями и сразу предоставляла полезные метрики.
Для руководителей
ИТ‑руководители (CTO, CIO, тимлиды) работают с агрегированными показателями. Им не требуется информация о загрузке отдельного сервера. Визуализация для руководителей строится на аналитике, сводных показателях и трендах, позволяющих оценить общее состояние инфраструктуры.
Владельцы информационных систем и бизнес‑заказчики часто предъявляют индивидуальные требования к отображению данных. Типичный запрос — простые и наглядные индикаторы состояния по принципу светофора: зелёный, жёлтый, красный. При этом требования к визуальному оформлению могут существенно различаться у разных заказчиков, и здесь стандартное техническое задание уступает место индивидуальному подходу.
Владельцы информационных систем и бизнес‑заказчики часто предъявляют индивидуальные требования к отображению данных. Типичный запрос — простые и наглядные индикаторы состояния по принципу светофора: зелёный, жёлтый, красный. При этом требования к визуальному оформлению могут существенно различаться у разных заказчиков, и здесь стандартное техническое задание уступает место индивидуальному подходу.
Комплексные решения: мониторинг + визуализация
Как обеспечить потребности всех категорий пользователей? Ответ — в комплексном подходе, где мониторинг и визуализация работают как единая система.
«Пульт» — система инфраструктурного мониторинга. Продукт решает задачи сбора метрик, генерации событий и алертинга (автоматического оповещения при возникновении проблем). Поддерживает совместимость с экосистемой Zabbix, что упрощает миграцию.
«Графиня» — платформа визуализации, собственная разработка «Лаборатории Числитель», созданная с нуля. Интерфейс максимально приближен к Grafana, чтобы пользователям не приходилось переучиваться. Среди возможностей платформы: интерактивные витрины данных с широким набором виджетов (графики, таблицы, индикаторы); поддержка различных источников данных; гибкая ролевая модель (пользователь, оператор, продвинутый оператор и администратор); доступ через корпоративную авторизацию; динамическое клонирование виджетов.
Плагины для подключения источников данных вынесены в отдельную архитектурную сущность. Их может разрабатывать любой специалист на любом языке программирования, соблюдая определённый контракт взаимодействия с бэкендом «Графини».
«Пульт» — система инфраструктурного мониторинга. Продукт решает задачи сбора метрик, генерации событий и алертинга (автоматического оповещения при возникновении проблем). Поддерживает совместимость с экосистемой Zabbix, что упрощает миграцию.
«Графиня» — платформа визуализации, собственная разработка «Лаборатории Числитель», созданная с нуля. Интерфейс максимально приближен к Grafana, чтобы пользователям не приходилось переучиваться. Среди возможностей платформы: интерактивные витрины данных с широким набором виджетов (графики, таблицы, индикаторы); поддержка различных источников данных; гибкая ролевая модель (пользователь, оператор, продвинутый оператор и администратор); доступ через корпоративную авторизацию; динамическое клонирование виджетов.
Плагины для подключения источников данных вынесены в отдельную архитектурную сущность. Их может разрабатывать любой специалист на любом языке программирования, соблюдая определённый контракт взаимодействия с бэкендом «Графини».
Принцип «пирога»: трехуровневая визуализация
При построении системы визуализации хорошо зарекомендовал себя принцип трёхуровневой организации дашбордов с возможностью перехода от общего к частному.
Уровень 1. Единое окно. Наглядный обзор ключевых событий ИТ-инфраструктуры по технологическим доменам. Показываются индикаторы состояния групп объектов: сеть, СХД (системы хранения данных), СРК (системы резервного копирования), инфраструктурные сервисы, СУБД. Если в группе есть открытые события, индикатор меняет цвет. Пользователи этого уровня: дежурная смена, ИТ-руководители.
Уровень 2. Обзорный. Сводный дашборд состояния группы однотипных устройств. Здесь применяется модель здоровья — таблица, где для каждого объекта отображаются ключевые метрики: текущее состояние, средняя загрузка, количество событий. Пользователи: дежурная смена, службы эксплуатации.
Уровень 3. Карточка устройства. Детализированная аналитика по конкретному объекту: графики, таблицы, события, логи. Даже для разных типов объектов рекомендуется поддерживать стандартизированную структуру карточки, чтобы любой специалист мог быстро сориентироваться. Пользователи: службы эксплуатации.
Переходы между уровнями организуются через ссылки: клик на индикатор открывает обзорный дашборд, клик на название устройства — его карточку.
Уровень 1. Единое окно. Наглядный обзор ключевых событий ИТ-инфраструктуры по технологическим доменам. Показываются индикаторы состояния групп объектов: сеть, СХД (системы хранения данных), СРК (системы резервного копирования), инфраструктурные сервисы, СУБД. Если в группе есть открытые события, индикатор меняет цвет. Пользователи этого уровня: дежурная смена, ИТ-руководители.
Уровень 2. Обзорный. Сводный дашборд состояния группы однотипных устройств. Здесь применяется модель здоровья — таблица, где для каждого объекта отображаются ключевые метрики: текущее состояние, средняя загрузка, количество событий. Пользователи: дежурная смена, службы эксплуатации.
Уровень 3. Карточка устройства. Детализированная аналитика по конкретному объекту: графики, таблицы, события, логи. Даже для разных типов объектов рекомендуется поддерживать стандартизированную структуру карточки, чтобы любой специалист мог быстро сориентироваться. Пользователи: службы эксплуатации.
Переходы между уровнями организуются через ссылки: клик на индикатор открывает обзорный дашборд, клик на название устройства — его карточку.

Советы по автоматизации дашбордов
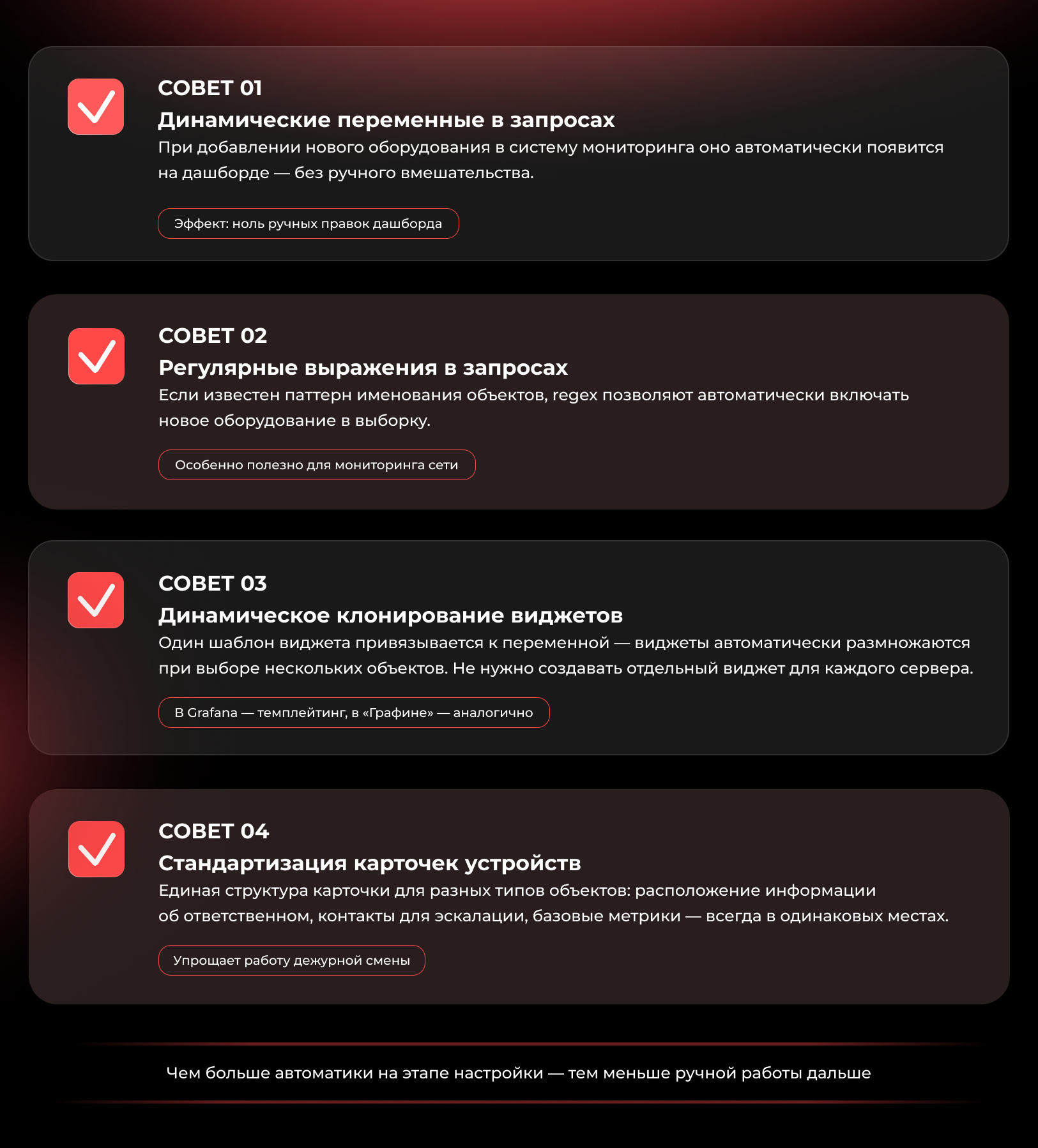
При создании комплексной платформы визуализации стоит учитывать несколько практических рекомендаций по автоматизации дашбордов.
Динамические переменные в запросах. При добавлении нового оборудования в систему мониторинга оно автоматически появится на дашборде без ручного вмешательства.
Регулярные выражения в запросах. Если известен паттерн именования объектов, регулярные выражения позволяют автоматически включать новое оборудование в выборку. Инструменты мониторинга сети особенно выигрывают от этого подхода при регулярном добавлении нового оборудования.
Динамическое клонирование виджетов. Нет необходимости создавать отдельные виджеты для каждого сервера. Достаточно создать один шаблон и привязать его к переменной — виджеты автоматически размножатся при выборе нескольких объектов. В Grafana это называется темплейтинг, аналогичная функциональность реализована в «Графине».
Стандартизация карточек устройств. Для разных типов объектов рекомендуется единая структура: расположение информации об ответственном, контакты для эскалации, базовые метрики. Это упрощает работу дежурной смены.
Динамические переменные в запросах. При добавлении нового оборудования в систему мониторинга оно автоматически появится на дашборде без ручного вмешательства.
Регулярные выражения в запросах. Если известен паттерн именования объектов, регулярные выражения позволяют автоматически включать новое оборудование в выборку. Инструменты мониторинга сети особенно выигрывают от этого подхода при регулярном добавлении нового оборудования.
Динамическое клонирование виджетов. Нет необходимости создавать отдельные виджеты для каждого сервера. Достаточно создать один шаблон и привязать его к переменной — виджеты автоматически размножатся при выборе нескольких объектов. В Grafana это называется темплейтинг, аналогичная функциональность реализована в «Графине».
Стандартизация карточек устройств. Для разных типов объектов рекомендуется единая структура: расположение информации об ответственном, контакты для эскалации, базовые метрики. Это упрощает работу дежурной смены.
Выводы
Эффективный мониторинг ИТ‑инфраструктуры включает в себя не только сбор метрик, но и их правильную визуализацию для разных категорий пользователей. Комплексный подход на примере связки «Пульта» и «Графини» позволяет закрыть потребности всех категорий пользователей. Оба решения внесены в реестр российского ПО, что решает задачу импортозамещения. Трёхуровневая организация дашбордов позволяет каждому пользователю получать именно ту информацию, которая ему необходима, на соответствующем уровне детализации.
Дмитрий Унтила: «Настало время Графини, чтобы сохранить всё то, что мы так сильно полюбили в Grafana, и улучшить всё то, от чего мы так сильно в ней устали».
Дмитрий Унтила: «Настало время Графини, чтобы сохранить всё то, что мы так сильно полюбили в Grafana, и улучшить всё то, от чего мы так сильно в ней устали».

